Roadmap to scaling the Rollups
Ethereum founder Vitalik Buterin recently posted a roadmap on how the current rollup solutions could be scaled to make them cheaper and faster.


@VitalikButerin has posted a roadmap on how the current rollups solutions could be scaled to make them cheaper and faster. A roadmap starting from calldata gas cost reduction and continuing with step-by-step rollout of sharding:
Let's dive into the steps in it.
Layer 2 Rollup solutions are designed to help scale decentralized apps by handling transactions off the Ethereum Mainnet (layer 1) while taking advantage of the robust decentralized security model of Mainnet. It reduces transaction cost drastically avoiding high gas costs.
By using optimism and arbitrum it have been 3-8X lower than ethereum where ZK based rollups like ZKsync, Polygon Hermez with better data compression techniques have been successful to make it 40-100X lower than ethereum.

Data Sharding
It has been discovered that data sharding might overcome the long-term shortcomings in rollups. It would add 1-2MB/sec of dedicated data capacity to the chain for rollups. The plan lays forth strategy for gaining faster access to data space and improved security for rollups.
Step 1: reduce tx calldata cost
Transaction calldata is used in existing rollups, immediate approach for increasing rollup speed & lowering costs in short term is to reduce cost of tx call data, though it may require some additional logic to prevent very unsafe edge cases.
EIP 4488 will decrease transaction calldata gas cost, and add a limit of how much total transaction calldata can be in a block. Increasing data space available to rollups to a theoretical max of ~1 MB per slot and decrease costs for rollups by ~5x.
Step 2: Few shards
Proper Sharding is a long process, but start would be implementing the business logic of sharding specification while keeping the shards low(e.g 4). This will Increase rollup data space by~2MB/slot (250 kB/shard * 4 shards + prev expanded calldata~1MB
Step 3: N shards, committee-secured
Increasing the shards from 4 to 64 where shards data would go into subnets. its now viable as P2P layer (layer used by nodes to communicate with each other) would have hardened to allow this exapnsion.
The security of the data availability would be honest-majority-based, relying on the security of the committees. This would increase rollup data space to~16 MB per slot (250 kB per shard * 64 shards); Assuming that RollUps will have migrated off of the exec chain.
Step 4: Data Availability Sampling (DAS)
Each node would download small portion of total data. Each node check every blob, but rather than downloading whole blob they privately select N random indices within blobs. To verify, at least half of data in each blob is available
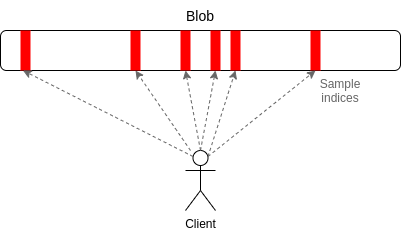
If less than half of data is available, then it is almost certain that at least one of the indices that any given client samples will not be available, and so the client will reject the blob. It's efficient, as client download only a small portion of each blob to verify.
Also, highly secure as even a 51% attacker cannot trick a client into accepting unavailable blobs. It is to ensure a higher level of security, protecting users even in the event of a dishonest majority attack, Once DAS is fully introduced, sharding rollout is complete.
What will change for rollups?
With sharding, the rollups would not be able to send rollup data as a part of submitting rollup transaction block. In a 2 step process, Data publication step puts data on chain(into shards) and next step submits the header+proof to underlying data.
Optimism & Arbitrum already use a two-step design for rollup-block submission, so this would be a small code change for both. For ZK rollups, somewhat more tricky, because a submission transaction needs to provide a proof that operates directly over the data.
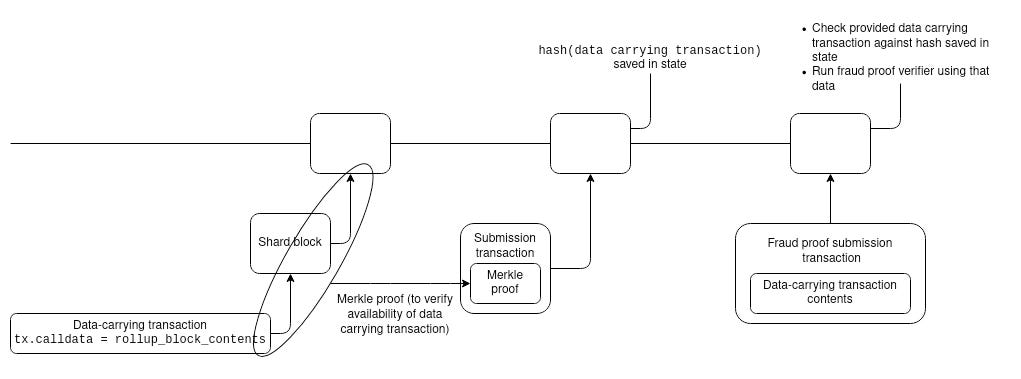
Who would store historical data under sharding?
A necessary requirement for increasing rollup data space, is removing property that Ethereum core is responsible for permanently maintaining all data it comes to consensus on. EIP 4488 leads to chain size ~3TB/year. 4 shards adds ~2.5TB/yr while 64 shards leads to ~40TB/yr.
With sharding, the data would be ~40TB/year which is not feasible for normal users(with 1-2TB HDD) to store. The leading solution to this is EIP 4444, which removes node operators’ responsibility to store blocks or receipts older than 1 year. In the context of sharding, this period will likely be shortened further, and nodes would only be responsible for the shards on the subnets that they are actively participating in.
if the Ethereum core protocol will not store this data, who will?
Nodes running with 32 ETH validator slot could easily pay for the hardware to store entire post-sharding chain for staking rewards. So there would be always people who will store data. Solutions like block explorers would always store as its their business, Protocol based solution where people are incetivized to store could be explored.
On-chain data query protocols like @graphprotocol could create incetivized data marketplaces where clients pay servers for historical data with Merkle proofs of its correctness. In the long term, it’s very possible that history access will be more efficient through these second-layer protocols than it is through the Ethereum protocol today.
Conclusion
Above roadmap is focused to make rollups cheaper in the very near term, lowering the costs ~5x using the calldata cost reduction. In future it would be scaled practically limitless by implementing the proper sharding and DAS.
Endnote
For more interesting crypto developments and updates, subscribe to our daily newsletter.
https://bit.ly/2W0kYW1
#CryptoMatters